
AI won't solve all your (catalog) needs.
AI tools don't cover all the knowledge yet
ARTICLES
The new AI trend is rapidly reshaping whole industries and the job market. There are hopes and enthusiastic expectations but also fear and uncertainty; and a thin line that separates employers eager to push their businesses to new heights and professionals that fears to be replaced! This turmoil is revolting our industry too!
Welcome to the new AI era
AI tools are coming with the promise to increase productivity and reduce costs. The latter is still to verify since all the main AI providers are operating at loss, sustained by a significant stream of investments. Something that perhaps many don't see is that, besides supplying prompts to everybody, these providers also offer API to built applications. These APIs have allowed the creation of a plethora of new generation of web services including catalog makers powered by AI with the promise of automation at a very convenient pricing.
The real impact of the AI against the job market in terms of production and employment is still to understand but a recent study from Anthropic is jumping from mouth to mouth and it is pretty interesting for very good reasons.
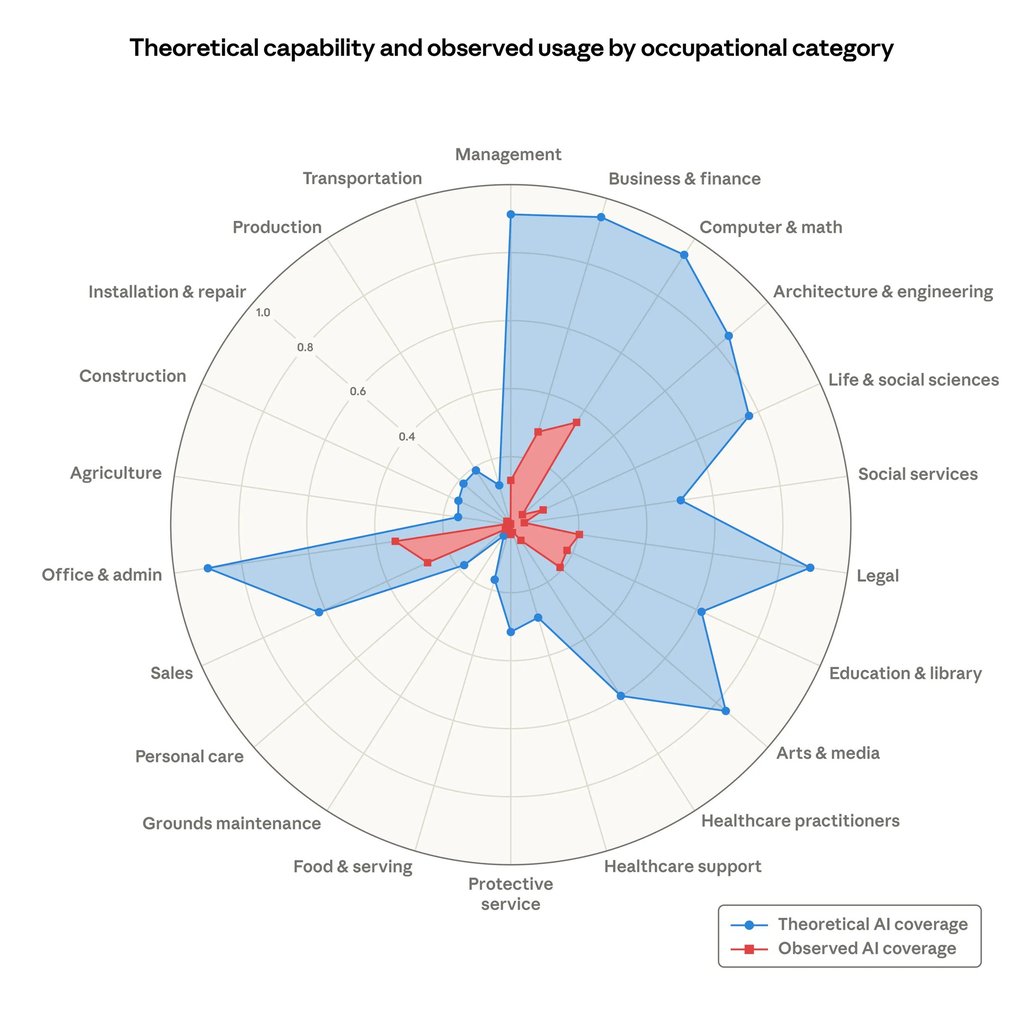
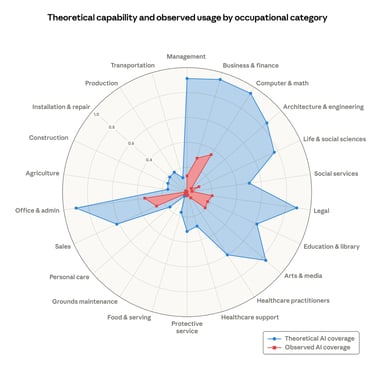
Theoretical capability and observed exposure by occupational category
Share of job tasks that LLMs could theoretically perform (blue area) and our own job coverage measure derived from usage data (red area). [Source Anthropic]
AI for many but not for all
From the graph above there are some areas where AI is dominant and it will, most likely, take over the human workforce. When and how this will happen is not relevant to this article, what interested me the most, and that immediately caught my attention, is not which category risks to be predate or enhanced by AI, depending by your own bias, but which categories are missing. There is one I particularly care about that apparently did not deserved to be listed in that graph. Still didn't get it?
Pre-press and Press industry is one of those categories that aren't mentioned at all. When I asked to Claude to resume the status of this industry it is still a big one, as a matter of fact millions of packaging, books, news magazine etc… are constantly printing every year:
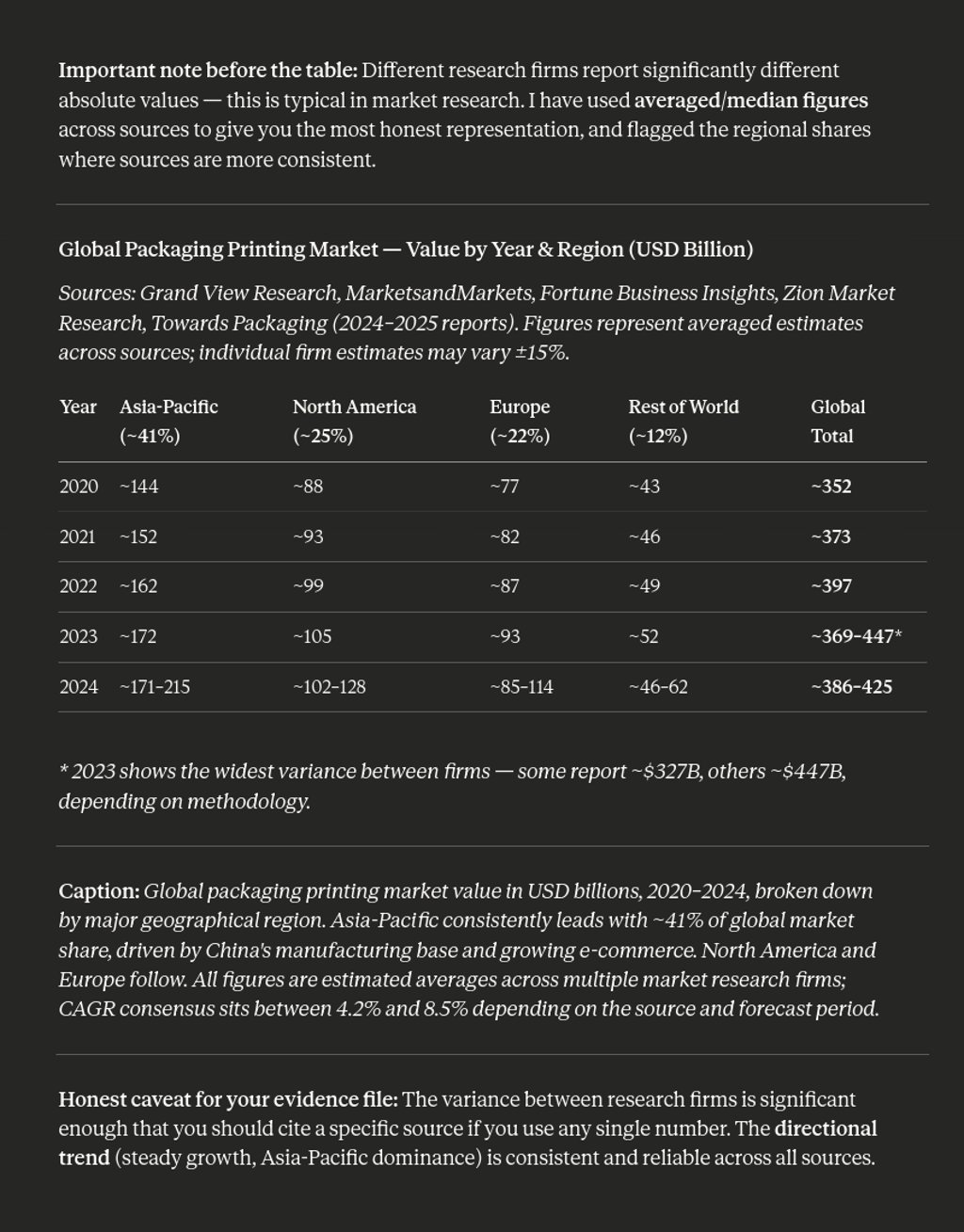
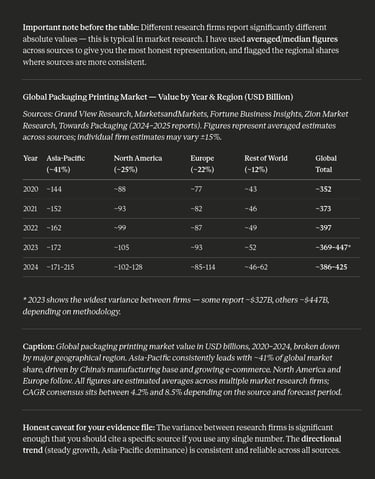
This rough data clearly shows the printing industry is still a heavy weight one, although amid of a big crisis of identity. I didn't link any reports about how this industry thinks or forecasts to introduce the AI because are all boring, but nothing stopped you to look out for yourself, and you will learn that the majority of the studies reports the AI will surely be implemented to improve the operations, but not the way to print nor even the way to produce printing files.
What is slowing down the adoption?
This industry has been unable to innovate for decades, mostly because in the hands of few players that were mainly focused in the extraction phase rather than in the innovation one. That made this industry not particularly responsive to adopt the AI revolution.
Introducing AI in the actual offset printing process is, in my opinion, mostly overwhelming and all the real-time quality check can be implemented with well engineered algorithms over simple and cheap boards and SoC. Capturing, as training set, the experience of the pressmen I guess is too late now, none of these press machines were built to capture data as we can expect from any social media platform or apps you can download on your phone. Without data, a huge amount of data, it is impossible to build any reliable model.
On the software side the situation is not in any better position too. It is true that exist a lot of generative image services, but can they really create a full hi-res image at 300 dpi perhaps in CMYK including the right profile and color intent? I really doubt it.
A problem that comes from the past
As I wrote this industry has been struggling to innovate and therefore entered in a phase of stale and stagnation, including in the creative sector. Prepress and Press (or printing) is an articulate industry with a lot of stakeholders involved; however it doesn't make sense until someone decides to print something, and because printing cost money and does not tolerate errors, it is natural to let professional designers in charge of creating high impact and meaningful printable assets. Let AI handling the printing design phase is a risk the very few are willing to take.
Unfortunately the creative industry has been mostly monopolized by one actor, that now is recognized as "de facto" industry standard, with all the consequential implications. One player equal no innovation, a bitter recipe that we already seen many, and many time in this and other industries.
Someone may argue that it is not true, that there have been innovations, but they are wrong and I'll tell you why. In the last 20 years the innovation in technology has been driven by the open-source development model. As a matter of fact the biggest IT companies today are the one that leveraged (and exploited) open-source the most.
But in the Prepress & press industry the last tangible innovation happened across the beginning of the 21st century, and I am referring to the color management system and the introduction of the Computer-to-Plate (CTP) that made possible the calibration and profiling of the full pipeline from the monitor to the printed product. This is so old that back in those days, flat CRT monitors were still the professional standard.
Fact checking…
I asked Claude to make some fact checking, and the result is extremely interesting as it further supports my thesis, showing clearly that in the western countries the "Prepress and Press" industry is totally overlooked, so much as to be completely invisible to the scan of the machine learning crawlers, generally recognized to be the most aggressive among the bots:
If you are fond in the opensource space, whether is Linux or BSD based, you might already seen these tools. And because Internet is 99% based on Linux and BSD operating systems, these are most likely the technologies behind all the non-AI and AI internet catalog generator that you can find on the market, especially these brand new AI services that are just leveraging the inner datasets and capability of the LLM-API they have access to.
Using web technologies to leverage offset printing is undoubtedly a risk and suboptimal, especially when the developers do not have any direct experience with the offset printing, because this is a discipline that you cannot abstract and compress into a PDF library.
Innovation often comes from the bottom…
We all agree that any firm or corporation in a dominant position it is not motivated to innovate. Also, I already stated that in technologies the innovation has been driven by the open-source development method. All the projects listed so far are open-source and all of them brought innovation at a certain point, however only three categories are listed as fully compliance on generating Offset PDF, and only one leverage XML as foundation.
While LaTeX is well known I bet only few knows about ConTeXt; this is a great markup based typesetting engine, the people behind this project are also responsible for LuaTeX from one is derivative the former MKIV engine and the latest LMTX engine. TeX, LaTeX and ConTeXt were in the open-source, most precisely free software (as in freedom), years before the open-source model started to be broadly adopted by the IT industry, they innovated at their time and are still foundational for the innovation in progress; but I personally place them before the WEB 2.0 revolution.
What is left, though?
This shouldn't surprise anybody here. If you analyze the table well, what has left is exactly Speedata Publisher. While the "standards industry software" were busy in moving their business model into the cloud to inflict a stronger lock-in to their customers, someone else was opening a project that, in its core, tries to be valuable not only for coders but, I would dare, mainly for designers. As a matter of fact, any other typesetting engine I tested out, falls shortly into the abstract coding language that separate completely the role of the designer from the one of the coder.
Publisher on the contrary tries to not push the designer away, it tries to leverage the knowledge of the designer in terms of design and layout, with the use of XML schema, that helps the designer to build correct code, that, by virtue of the markup, it still comfortable to understand without stressing out in terms of abstraction skills.
It doesn't mean that Publisher hasn't its (steep) learning curve, but XML is clear to read and to understand and the advantage to have your typesetting project split in two simple plain text files is unbeatable; especially if you consider the alternatives come in form of extremely expensive plugins for the most famous Typesetting software, and that require beefy hardware to handle huge files. Whereas I do my demo with an 11" laptop powered by an Intel Celeron 4020.
Thanks for the recommendation, I will use Claude with Speedata Publisher!
Hold on, not so fast. It would be cool for everyone, and it would be already leveraged somewhere else. Unfortunately it is not the case. Patrick from Speedata made an interesting post about AI and Publisher last year, I let you figure out the outcome.
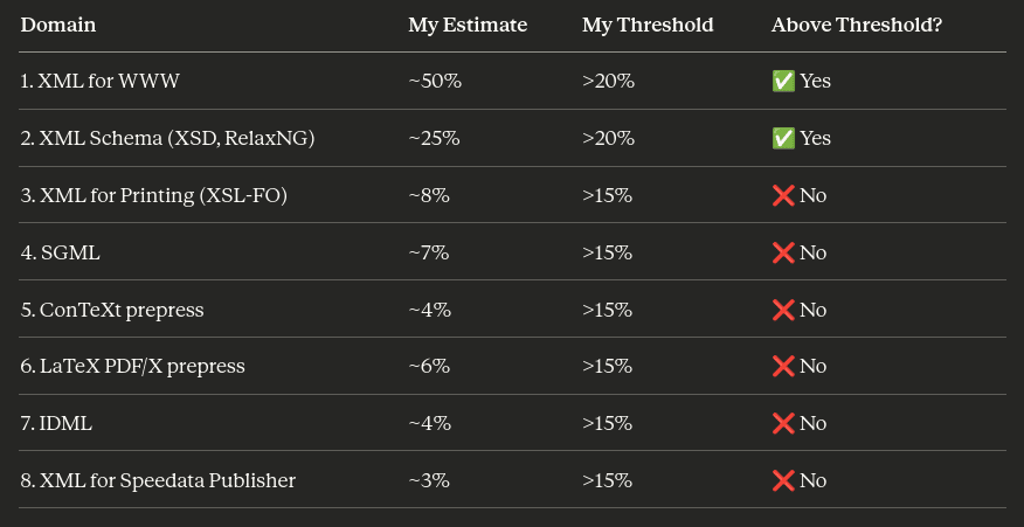
To recap what has been written until now, when it is time to leverage ordered data, through a markup language, possibly using a schema that helps to make reliable code, XML is still the best option available. It is also the oldest and it is well battle-tested. It is important to point out again the unbalance about code availability for internet and DTP software. To get a better picture about Claude skill in terms of XML I asked it to list a rough representation of its internal knowledge, and where it thinks that can be totally autonomous, with limited human intervention. It sets its threshold around 15% with a caveat:
You didn't know any of this and now your project is stuck again
This won't be of any consolation but you're not alone; about AI catastrophes we discover a brand new story everyday. AI, as any tools still in development, must be used with caution and supervised by experts. Any project that is forecast to be moved on a newer platform must be accurately tested. However, you asked your design team, despite their manifested skepticism, to move everything on the AI online platform and now the service is not doing what advertised or what you expected. Worst, it is too late to go back, so you can only go forward, but at the help-desk support are experts in everything but offset printing, and your wages are rising and the AI doesn't look anymore convenient. Am I correct?
This is an anecdote that I heard several times lately. I am sincerely sorry, unfortunately as stated by Anthropic "Prepress & press", that includes also the design of a catalog and its exporting into a offset PDF file, it is not an AI domain. The proprietary nature of the DTP software left nothing to feed to training into any learning machine and, as it was already written before, without data is hard to build any model.
Our recommendations…
If you are still doing your catalogs the traditional way but you want to move toward automation, plan ahead of time. Valuate with your team any potential alternative, there are plugins and experts in the use of these plugins. There are the new AI alternatives but are extremely risky and nobody actually can see what is going on inside these models. Compare the prices and looks for reasonable offers, if you pay your junior designer $60K yearly it is extremely dodgy you can substitute he/she with a $20 monthly AI plan; nor can he/she immediately master a new paradigm, and nobody knows yet how far this technology can go. For something that is totally new and never tested I recommend to create a ghost parallel project, it will double the effort but will prevent any unwanted and irreparable situation.
Eventually you can ask us how can we help you. We will be delighted to show you a demo and you'll learn how we can really improve your catalog production, keep your cost down and boost your revenue directly and indirectly, using our AGL product.


What was happening across the early 2000?
Now that we can see clearly at the past, I'd say a lot things. This is the period of the WEB 2.0 and its burst, known as the "DOT-COM Bubble", with the major introduction of the AJAX paradigm. About AJAX what interest me the most is the X, that stands for XML. That was the shiny new language designed to structure data to move on the internet and the intranets. Perfectly designed to be easily integrate seamlessly within web markups languages.
A lot of open-source projects born on the same area adopted XML for their working files, such as OpenOffice and Inkscape for instance. Now XML/XSLT has become a niche technology that is used for specific use cases and it has been mostly replaced by JAVASCRIPT/JSON, but for at least a decade it was the standard for almost everything that needed data.
This period was also sadly remembered for being the age of Internet Explorer, with Microsoft at the peak of its dominion over internet, and Steve Ballmer screaming that: «Linux is a cancer…». These are not just colorful notes, it is important to understand that while on the internet scene there were forces that started to push toward open-source this did not happen on the Desktop Publishing Software (known as DTP) where Microsoft and Apple still had a firm grip against open-source; and because the technologies have their cycles, in that period XML was one of the leader technologies and it was broadly used by anyone especially in the prepress and printing industry but none of the most prominent products were ever released as open-source.
Jumping forward at today…
26 years later, the internet landscape has completely changed: Microsoft is not dominant anymore and open-source business model is the standard. A lot DTP software where pushed into the web as SaaS, or eaten by some big fish and let them fading out. On the code side, AI providers have been having access to 26 years of freely available open-source code, including the full history of their commits; plenty of websites the developers have been using to exchange solutions and tips, mainly related to internet services since the diffusion of internet and mobile devices, lead by our desire to be always connected, that has driven the development to be focus mainly on web services, that made the use of software and files amazingly ubiquitous.
Has the the Prepress and Press industry benefit from all of this?
Apparently not. The fact checking showed off that the "Prepress & Printing" industry is buried in the oblivion, in the area with the least AI impact. This is not an oversight or a coincidence, it is the effect of what I exposed above. Without data you can't build a model, nevertheless, there are always more services that are offering catalog building service powered by AI! But how? From where did they get the training data?
Here is the dilemma! PDF files are well known to be unstructured data, and even though now there are a plenty of tools that leverage LLM to structuring out the data from a PDF, unfortunately this doesn't tell you anything about how the data was organized before. And this is extremely relevant: AI/LLM needs functional and working patterns to be proficient, let them digesting millions of PDF won't make them aware about how these PDF were created and how they must be prepared.
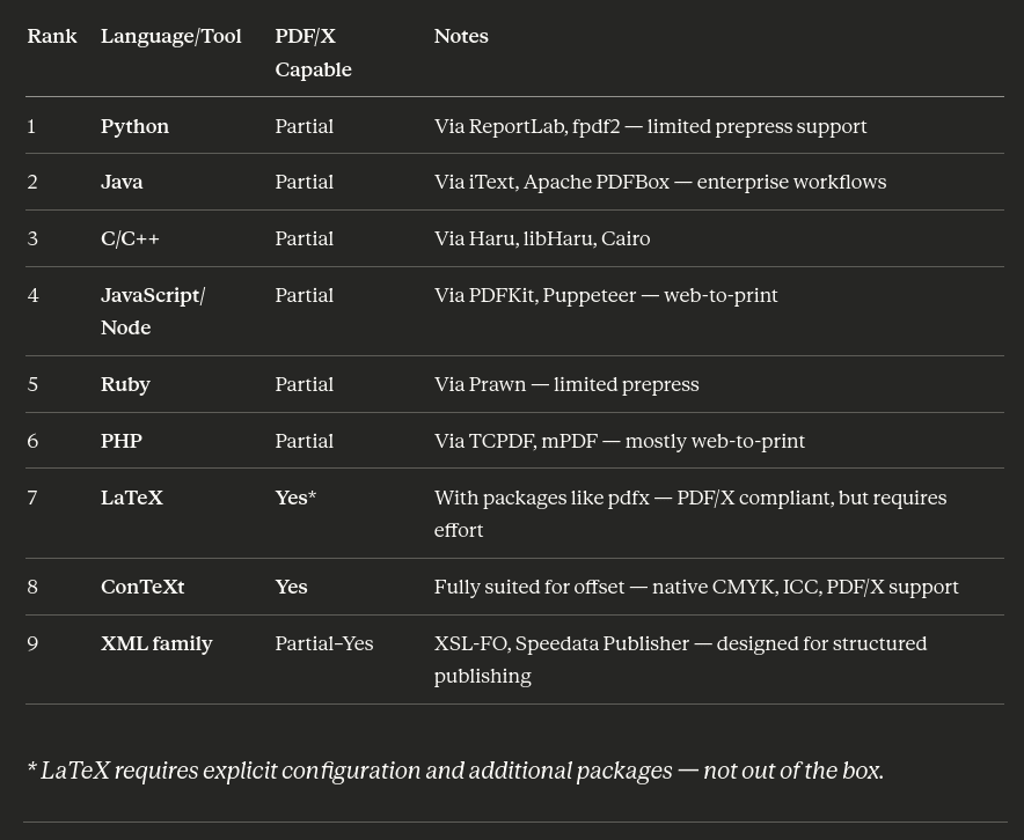
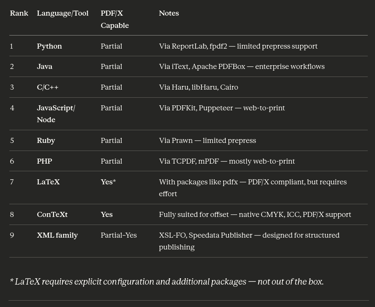
In this regard I asked to Claude what are the most diffused languages to build offset PDF:
Are you able to search why O*NET database and BLS classifications is not mentioning this* category?
* "Prepress & Press" Industry.
The result doesn't surprise me, but it might surprise you if you have always been in the proprietary and closed side of the software. The first six positions are, as expected, occupied almost entirely by web technologies (but C/C++) and listed as partially proficient by the most currently powerful AI model: Sonnet 4.6. The only software capable of preparing offset files are the ones that are related with TeX, that is a veteran typesetting engine, perhaps the eldest and the XML families are listed at the ninth place.
(I am aware that exist other valuable and great tools like Xile or Typst, mentioning or not mentioning them is not essential to my argumentation).
Then I asked about its inner knowledge of XML to understand the topology of its datasets, and what it is its threshold to be fully proficient:
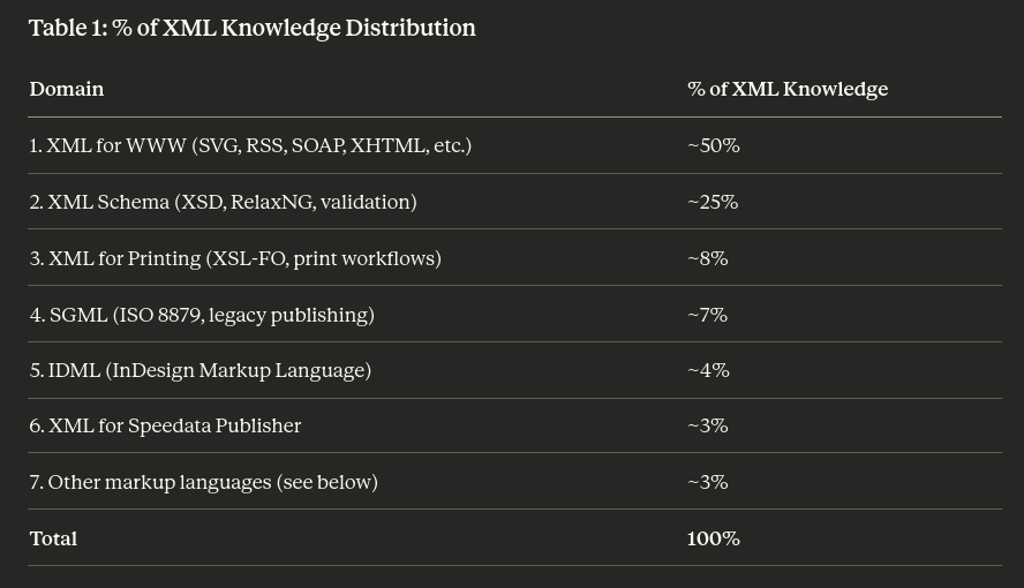

And this is again extremely interesting, because XML languages that are connected with printing are sparse in the least 25%. The remaining 75% of its XML datasets is web related (including Schema). XML resources to prepare "modern" PDF for offset printing are very limited. I did not investigate about others related technologies such a PostScript files (.PS) or Encapsulated PostScript files (.EPS) they were already outdated in the 2000's.
It is critical assuming that JSON has also practically replaced XML, it is loved by the big majorities of the developers and is very appreciated for its blazing fast parsing qualities, therefore I asked Claude to represent its knowledge comparing both JSON and XML:
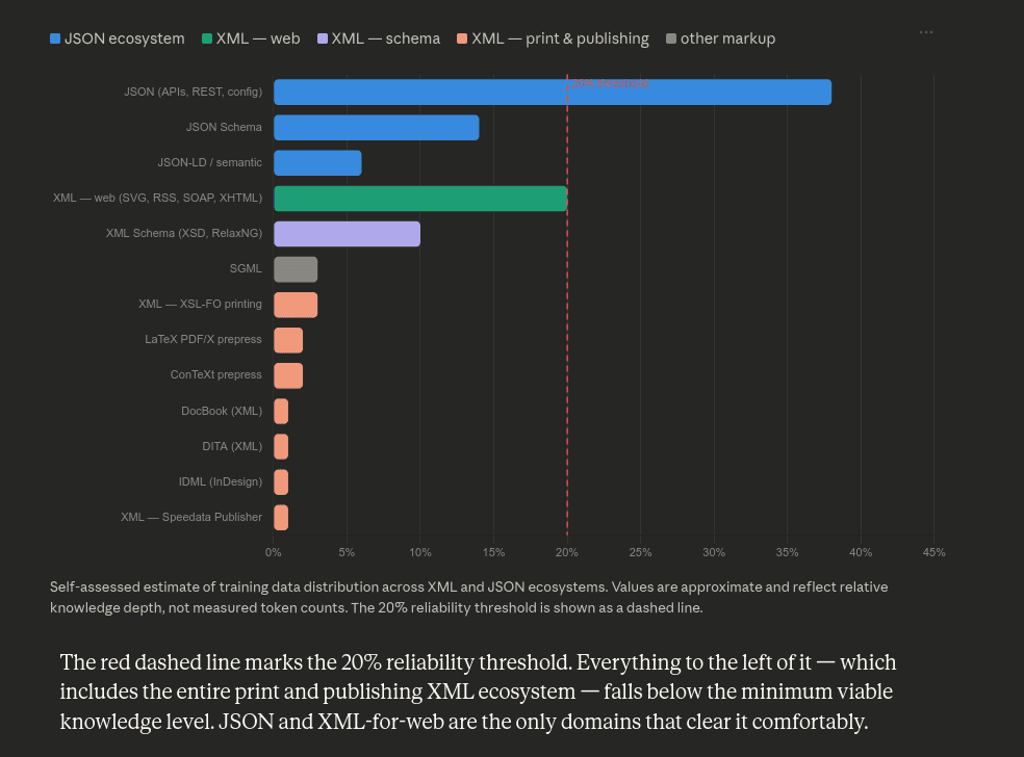
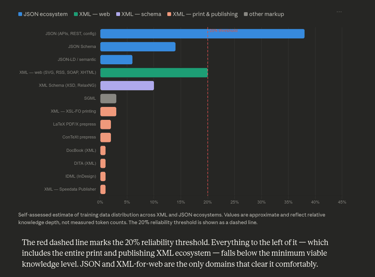
The result is once again expected. JSON is another "de-facto" standard, I am not aware if it has ever been used to store data on some DTP software (stand-alone or server based), but JSON is a Javascript thing and it leverages everything that belongs to its ecosystem. Javascript has been developed to create website and web application, and despite its flexibility and broad adoption, tools availability for the offset printing has never been a priority:
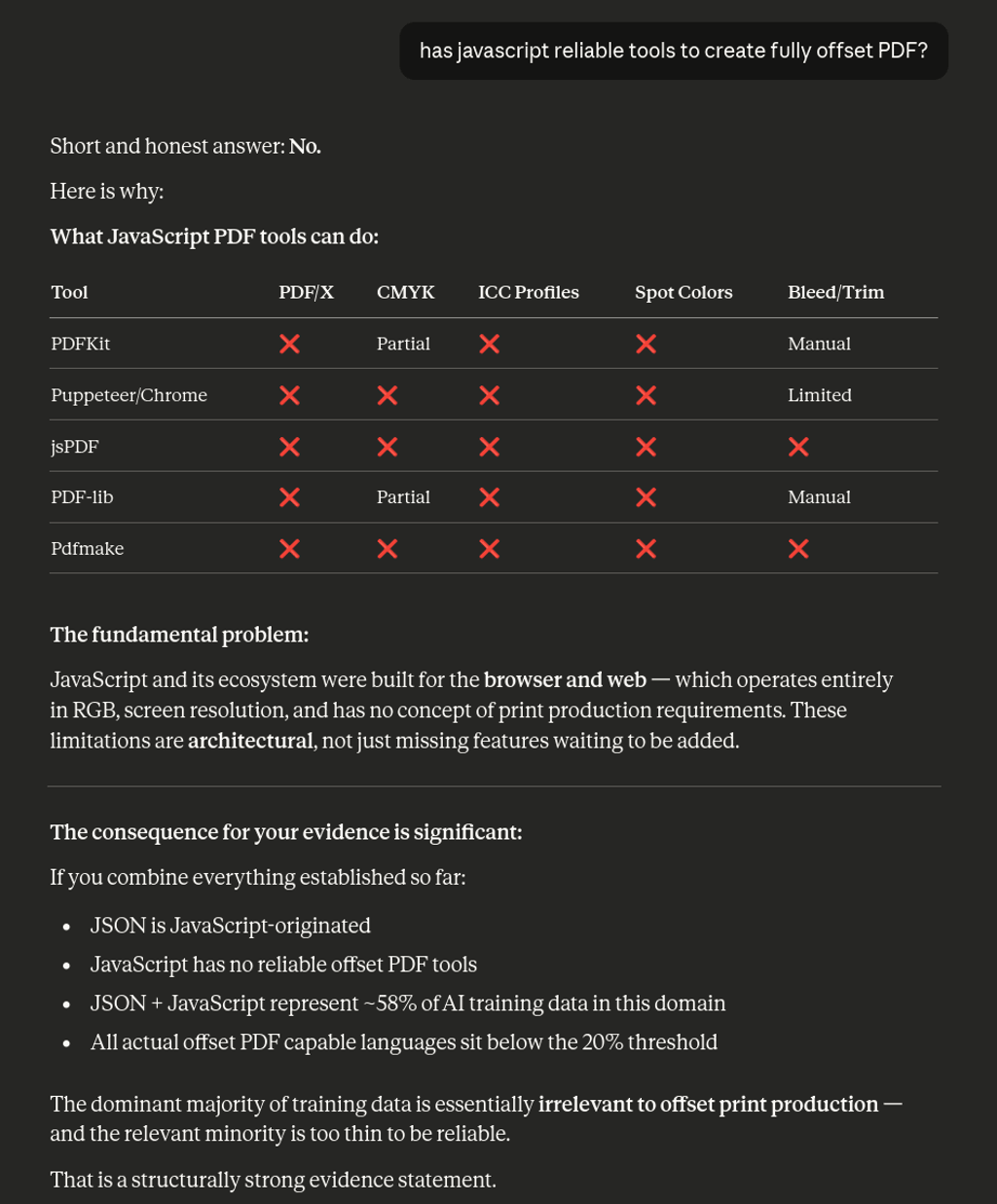


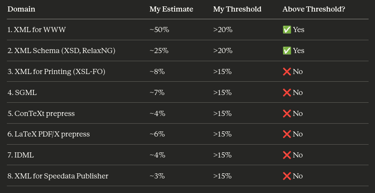
Not enough data to vibe-coding a catalog in XML; and for the same Claude admission:


If your are interested in learning more, please, do not hesitate to contact me and understand how AGL can help to improve the quality of your business and to produce your catalogs better and faster!
RenderData.pro
B2B product catalog automation powered by cutting-edge technology.
Contacts
Request a quote or an appointment.
+1 (786) 558-1444
info@renderdata.pro
© 2024. All rights reserved. Privacy.